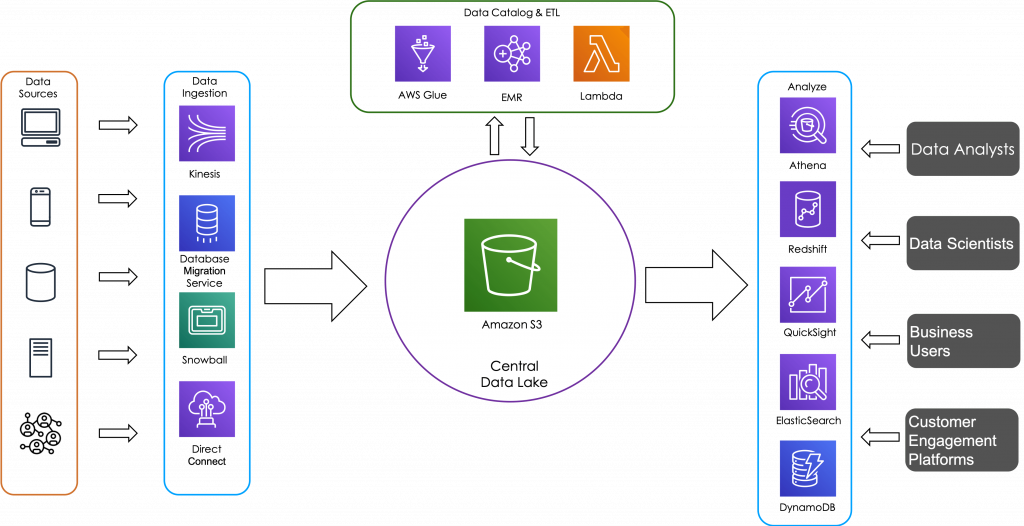
Data Lakes allow an organization to collect data from variety of data sources and store them all in a central repository. Once data is available in the Data Lake, various stakeholders can run different types of analytics – from dashboards to visualizations to real-time analytics, big data analytics and Machine Learning to gain better insights and drive decisions.
AWS Serverless technologies allows organizations to quickly build out such data lakes without the overheads of managing complex infrastructure. In this workshop, learn how you will use Serverless Technologies to quickly build data pipelines that gets answers from all your data. You will learn proven design patterns and architectures that helps in scaling your data lakes while keeping your costs optimized.
Overview of Data Lakes
- What are Data Lakes and its benefits
- Data Lakes Vs Data Warehousing
- Characteristics of a Data Lake
Module 1: Ingestion
- Amazon Kinesis: Ingest data from real-time data sources
- Overview of Kinesis Streams, Firehose and Analytics
- More ways to bring data to AWS – Database Migration Service, Glue, Storage Gateway, Snowball, AWS CLI and SDKs, Partner Tools
Module 2: Collection and Storage
- Amazon S3: Central storage for your Data Lake
- Storage Classes and Lifecycle Policies
- Best practices: File formats, partitioning, compression
Lab 1: Ingest real-time events data into Firehose and deliver data to S3
Module 3: Building a Data Catalog
- Why Data Catalog?
- Overview of AWS Glue Data Catalog
- Integration with other Data Services
- Glue Crawlers and Data Sources
Lab: Build Glue data catalog by crawling data
Quiz and Wrap Up
Module 4: Serverless Data Processing using AWS Glue
- Job authoring using AWS Glue
- Data Sources and Targets
- Built-in Glue Transformations
- Bring your own scripts and libraries
- Job scheduling, execution and monitoring
Demo 1: Build and run a Glue job to process ingested data
Module 5: Serverless Analytics using Amazon Athena
- Overview of Amazon Athena and its features
- Athena best practices – file formats, data partitioning, compression
Lab 3 : Query data in S3 data lake using Athena
Module 6: Modern BI using Amazon Quicksight
- Overview of Amazon Quicksight features
- Supported Data sources
- SPICE: In-memory data store for faster analytics
- Integrations with AWS data services
Lab 4 : Visualize your data lake using Quicksight and Athena
Module 7: Securing your Data Lake on AWS
- Shared Responsibility Model
- S3 security best practices
- Data Security best practices for Glue, Athena, QuickSight
Quiz and Course Wrap Up
- Quiz
- Summary of 3 days
- Further learning resources