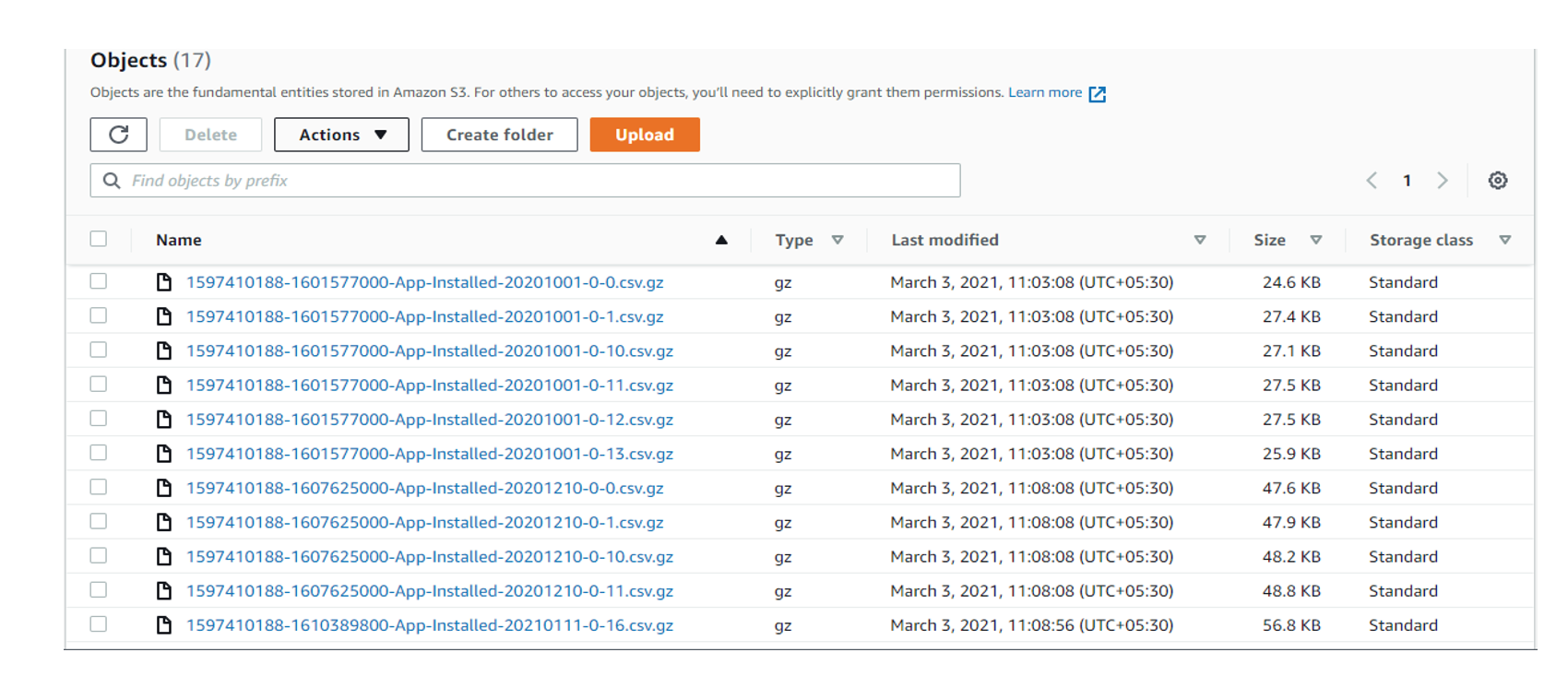
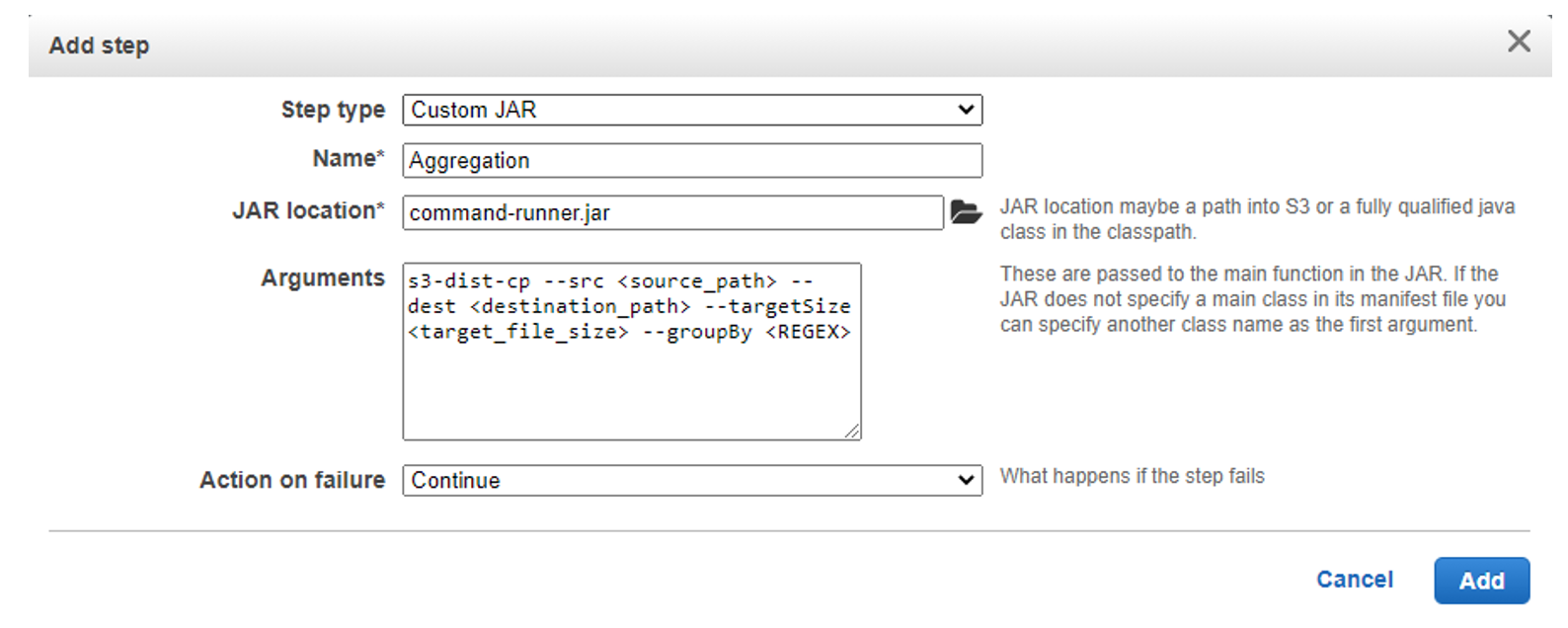
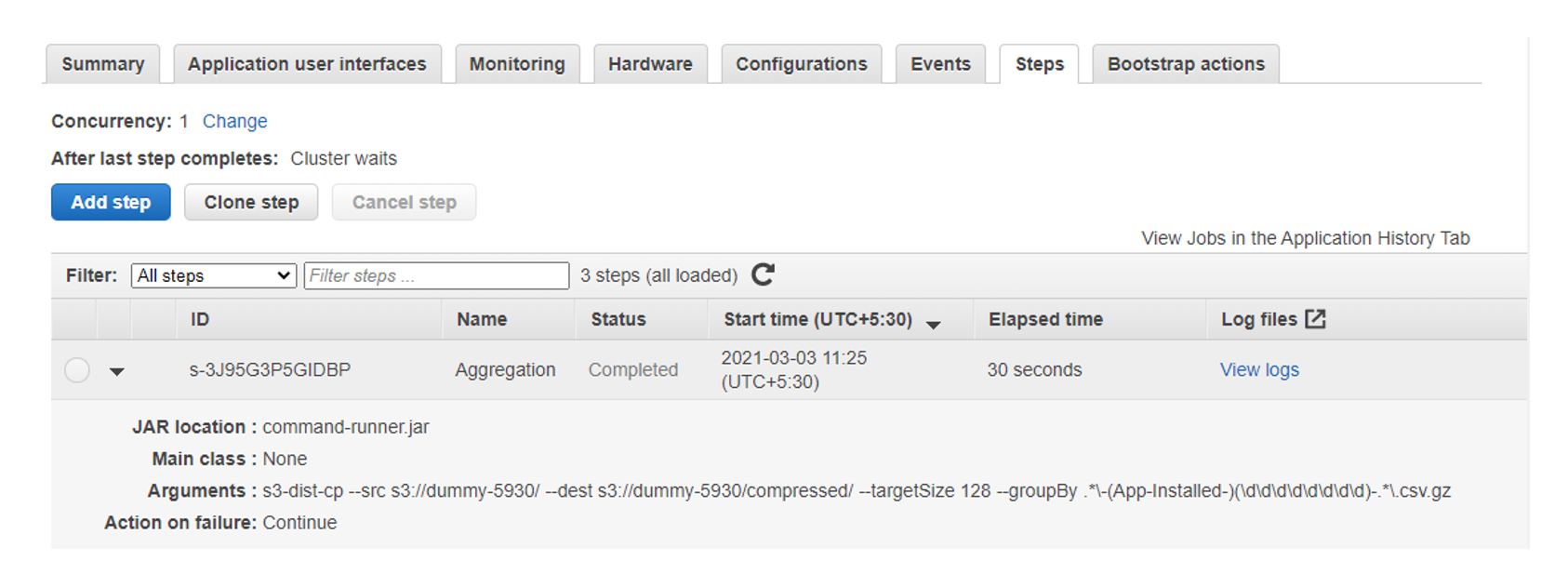
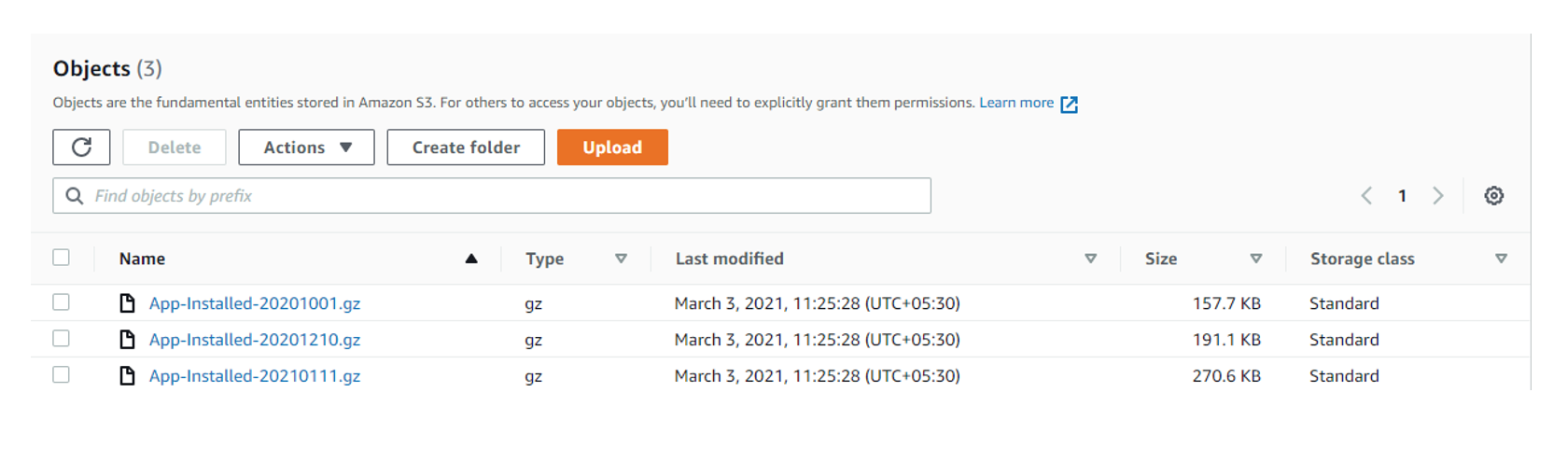
Customers that use Amazon EMR often process data in Amazon S3. We sometimes need to move large quantities of data between buckets or regions. In such cases, large datasets are too big for a simple copy operation.
Hadoop is optimized for reading a fewer number of large files rather than many small files, whether from S3 or HDFS. In the Hadoop ecosystem, DistCp is often used to move data. DistCp provides a distributed copy capability built on top of a MapReduce framework.
Amazon EMR offers a utility named S3distCp which helps in moving data from S3 to other S3 locations or on-cluster HDFS. S3DistCp can be used to aggregate small files into fewer large files of a size that we choose, which can optimize the analysis for both performance and cost.