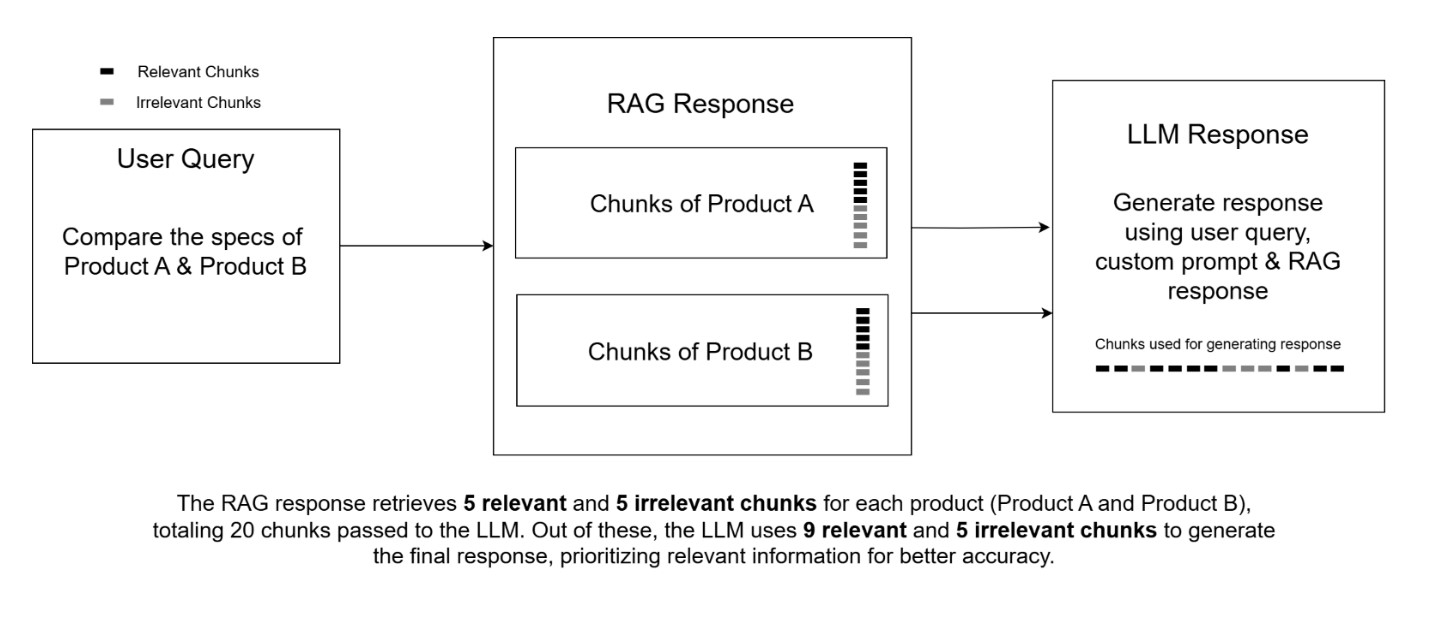
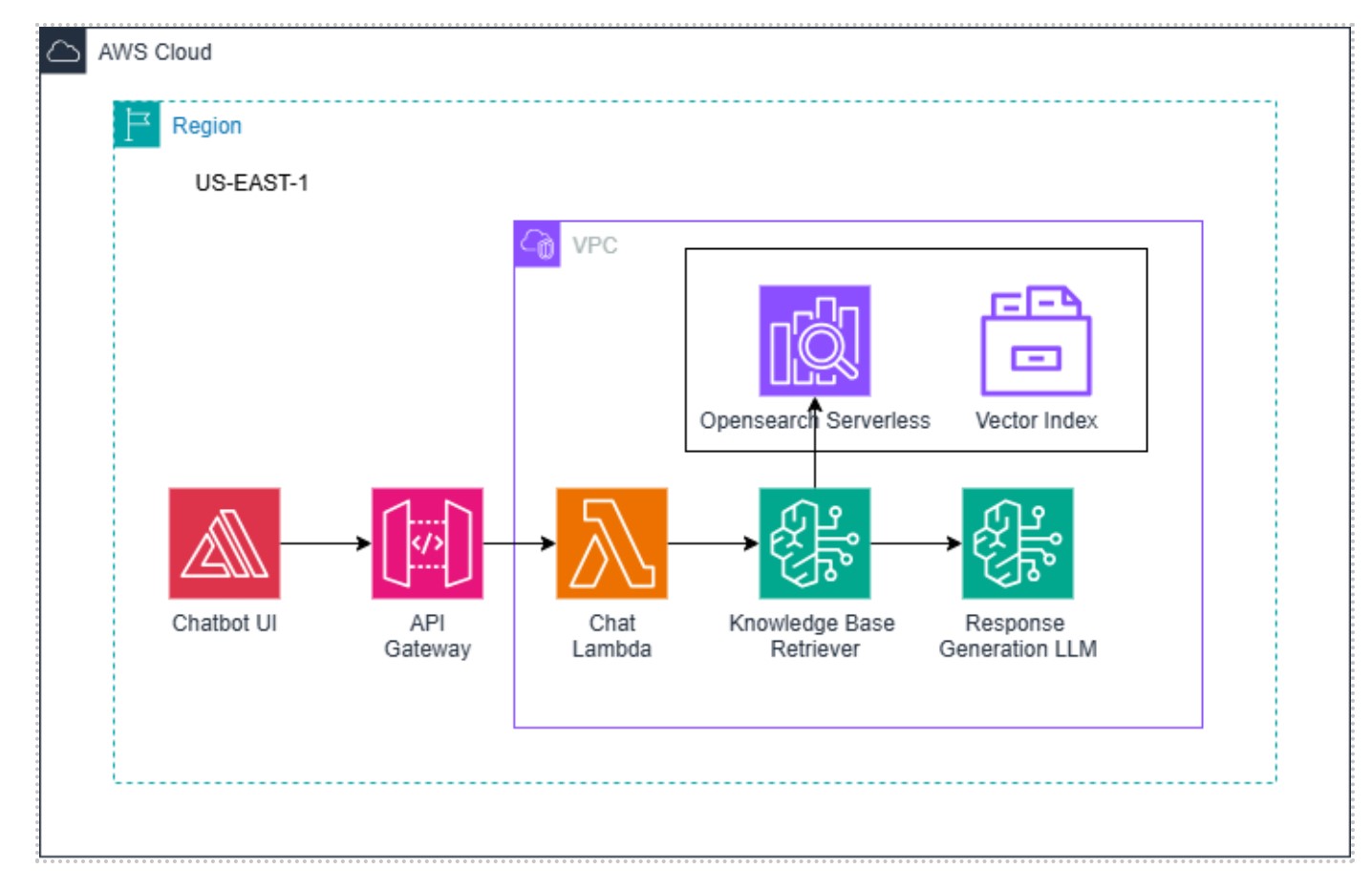
This blog addresses a key challenge in Retrieval-Augmented Generation (RAG) for NLP applications: ensuring relevance and accuracy in the information retrieved for response generation. Traditional approaches often retrieve data through semantic search, which, while effective, can lack precise contextual alignment, leading to irrelevant chunks being passed to the language model (LLM). This not only affects the quality of responses but also increases token consumption and computational costs.
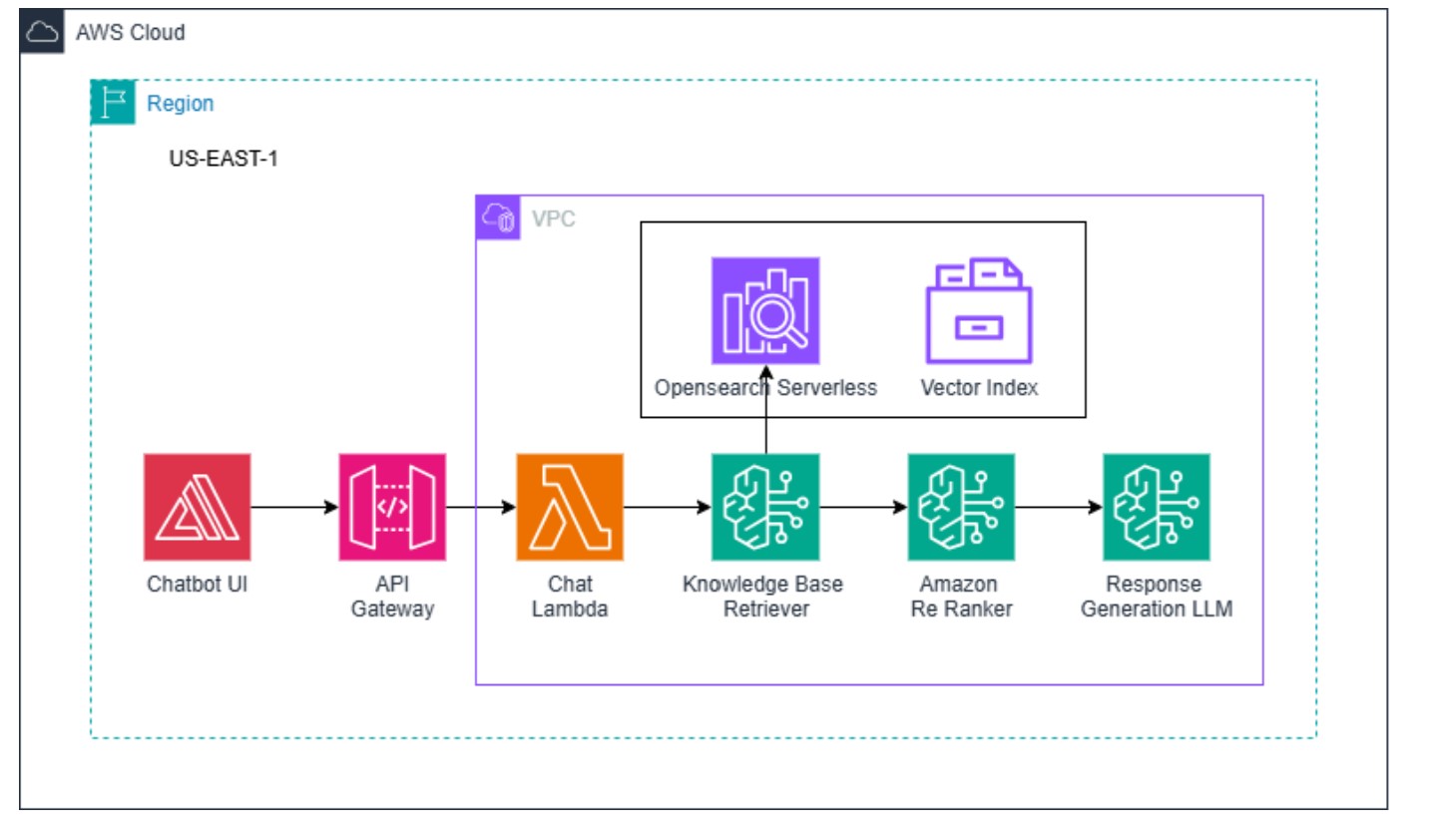
To solve this, we explore the introduction of a Re-Ranker layer between data retrieval and response generation. This layer filters and prioritizes the most relevant chunks, ensuring that only contextually appropriate information reaches the LLM. The result is improved accuracy, reduced token usage, and better overall performance of RAG-based systems.